

Previous studies typically rely on region-text similarity to discover pseudo region-text pairs from image-text pairs.
But a tricky thing is that, to get accurate similarity estimation, you need a region-level aligned vision-language sapce,
which in turn requires abundant region-text pairs to train.
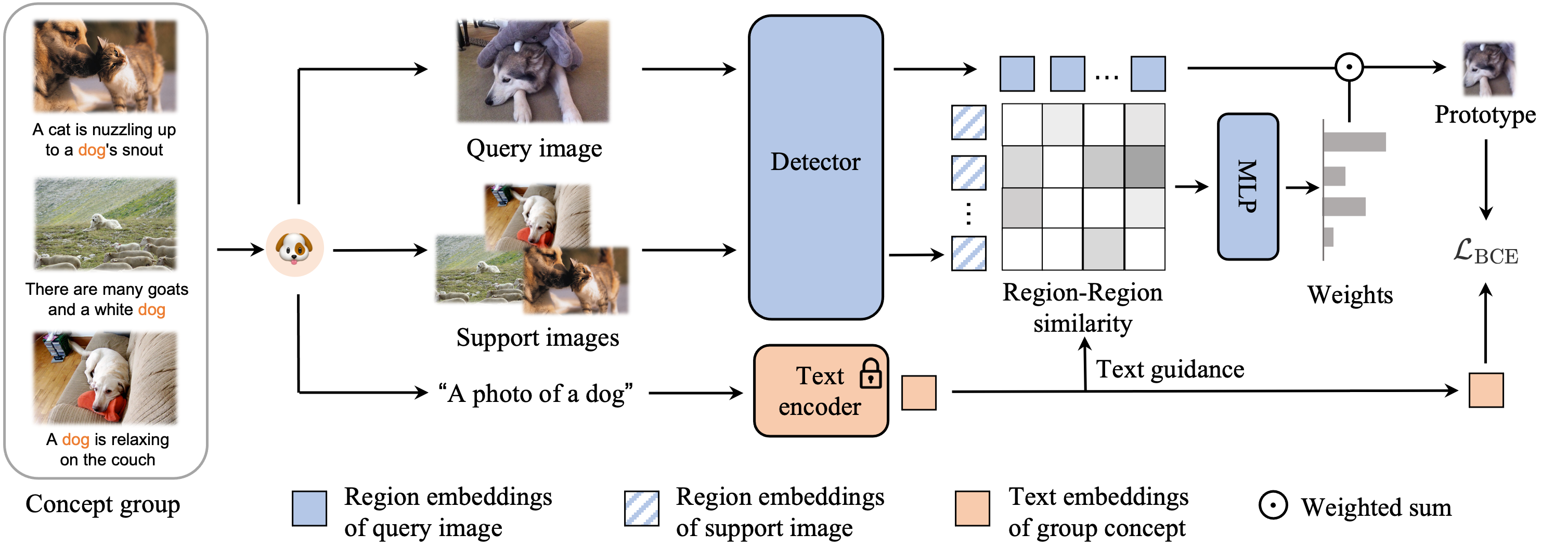
To break the chicken-and-egg problem, we introduce co-occurrence based region-word alignment,
which solely relies on region-region similarity to discover pseudo region-text pairs.
A nice property of co-occurrence is that you only need to scale up visual pre-training to get higher-quality pseudo-labels.
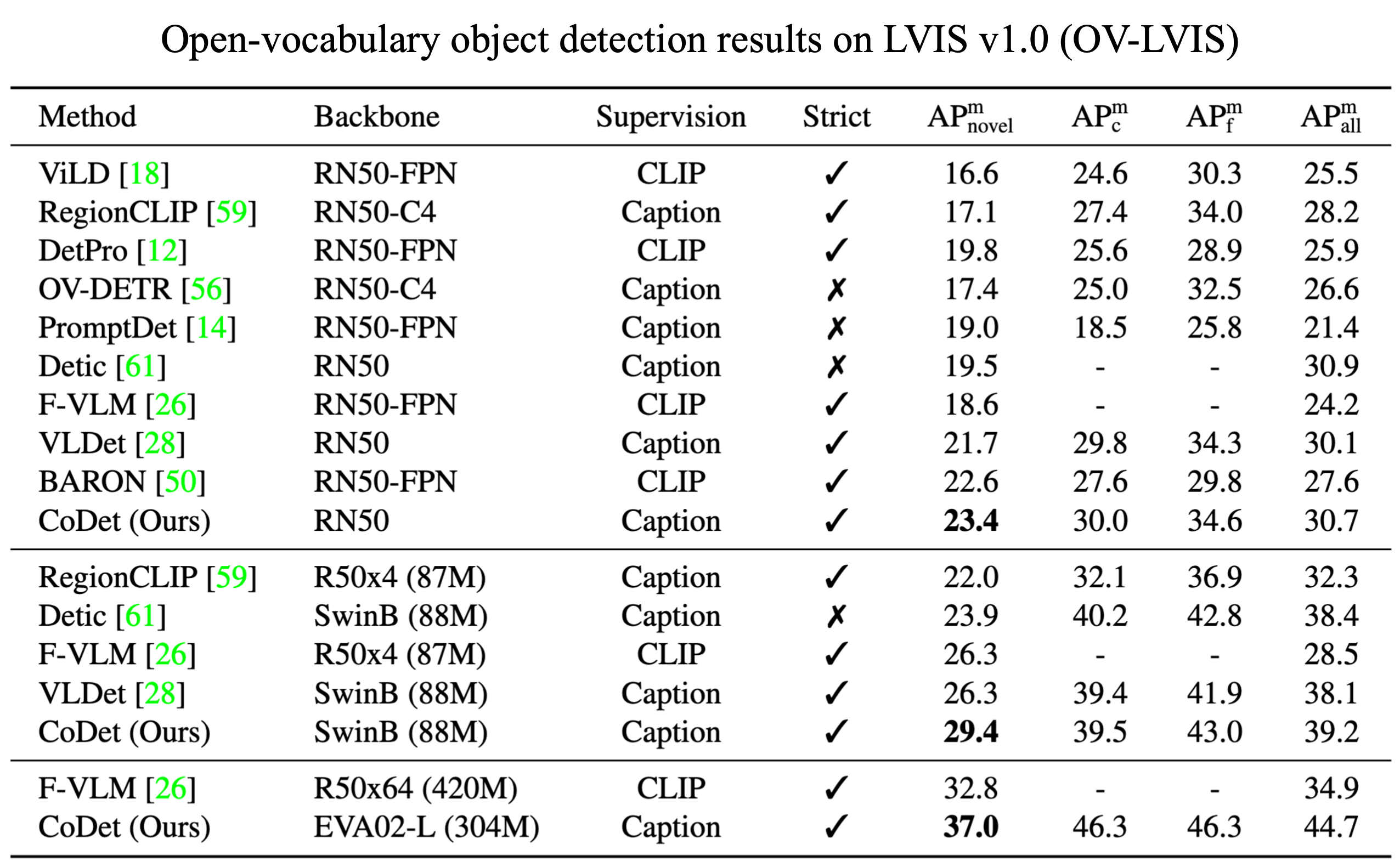
Deriving reliable region-word alignment from image-text pairs is critical to learn object-level vision-language representations for open-vocabulary object detection. Existing methods typically rely on pre-trained or self-trained vision-language models for alignment, which are prone to limitations in localization accuracy or generalization capabilities. In this paper, we propose CoDet, a novel approach that overcomes the reliance on pre-aligned vision-language space by reformulating region-word alignment as a co-occurring object discovery problem. Intuitively, by grouping images that mention a shared concept in their captions, objects corresponding to the shared concept shall exhibit high co-occurrence among the group. CoDet then leverages visual similarities to discover the co-occurring objects and align them with the shared concept. Extensive experiments demonstrate that CoDet has superior performances and compelling scalability in open-vocabulary detection, e.g., by scaling up the visual backbone, CoDet achieves 37.0 mask AP for novel classes and 44.7 mask AP for all classes on OV-LVIS, surpassing the previous SoTA by 4.2 and 9.8 mask AP, respectively.

@inproceedings{ma2023codet,
title={CoDet: Co-Occurrence Guided Region-Word Alignment for Open-Vocabulary Object Detection},
author={Ma, Chuofan and Jiang, Yi and Wen, Xin and Yuan, Zehuan and Qi, Xiaojuan},
booktitle={Advances in Neural Information Processing Systems},
year={2023}
}
}